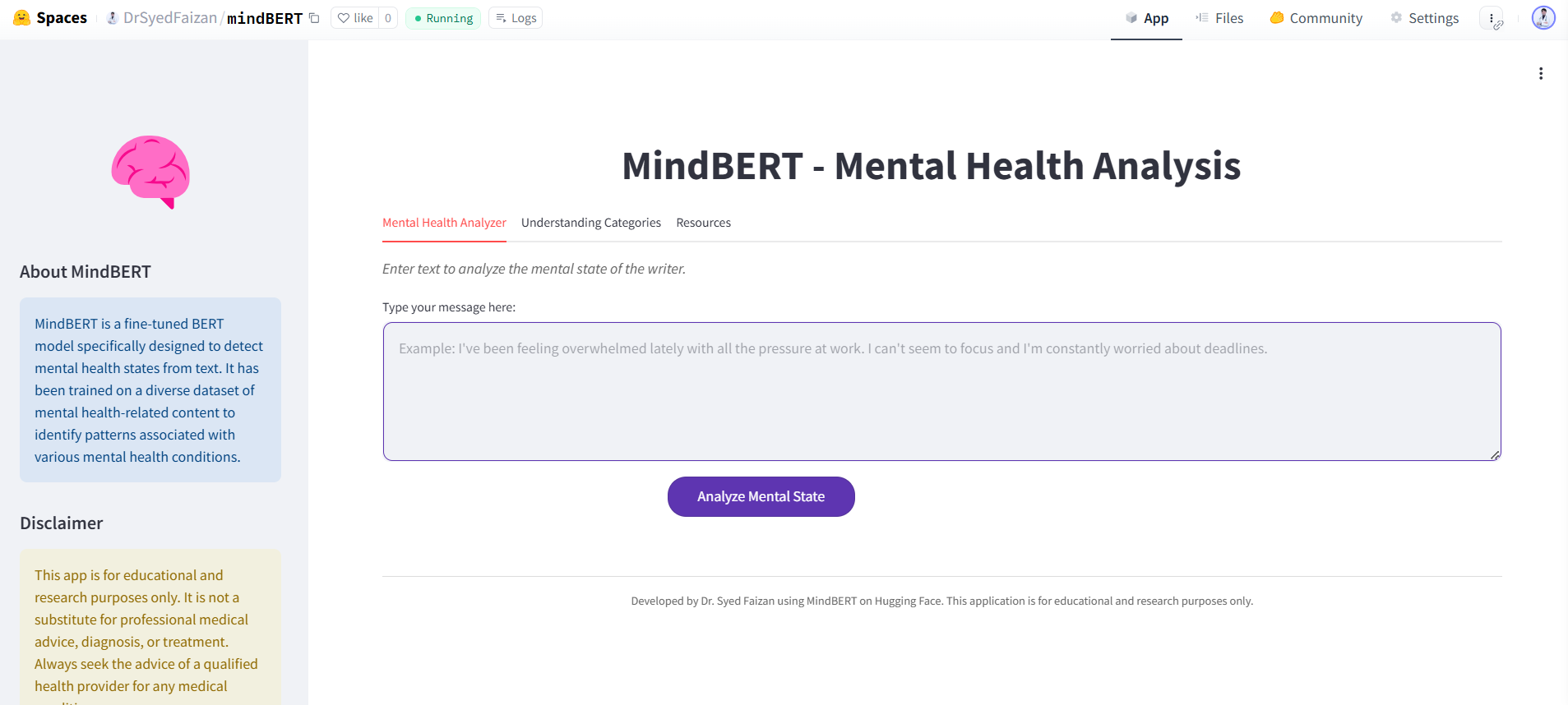
mindBERT is a transformer-based model fine-tuned for mental health text classification. It utilizes state-of-the-art Natural Language Processing (NLP) techniques to detect various mental health conditions from textual data. The model is trained on the 50,000 sentence mental health state labelled dataset and achieves high accuracy in detecting stress, depression, bipolar disorder, personality disorder, and anxiety.
👉 Try it here: mindBERT UI

| Epoch | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| 1 | 0.359400 | 0.285864 | 89.61% |
| 2 | 0.210500 | 0.224632 | 92.03% |
| 3 | 0.177800 | 0.217146 | 92.83% |
| 4 | 0.089200 | 0.249640 | 93.23% |
| 5 | 0.087600 | 0.282782 | 93.39% |



mindBERT is built using Hugging Face’s transformers library, leveraging BERT-base as a pre-trained backbone. The classification head consists of a dense layer followed by a softmax activation for multi-class classification.
The model was trained using PyTorch with the following configurations:
training_args = TrainingArguments(
output_dir="./results", # Output directory for results
evaluation_strategy="epoch", # Evaluate once per epoch
save_strategy="epoch", # Save model at the end of each epoch
learning_rate=2e-5, # Learning rate
per_device_train_batch_size=16, # Batch size for training
per_device_eval_batch_size=16, # Batch size for evaluation
num_train_epochs=5, # Number of epochs
weight_decay=0.01, # Weight decay strength
logging_dir="./logs", # Directory for logging
logging_steps=10, # Log every 10 steps
lr_scheduler_type="linear", # Linear LR scheduler with warmup
warmup_steps=500, # Warmup steps for learning rate
load_best_model_at_end=True, # Load best model at end of training
metric_for_best_model="eval_loss", # Monitor eval loss for best model
save_total_limit=3, # Limit checkpoints saved
gradient_accumulation_steps=2, # Simulate larger batch size
report_to="wandb" # Report to Weights & Biases
)To use mindBERT for inference, follow these steps:
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
model_name = "DrSyedFaizan/mindBERT"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# Sample text
text = "I feel so anxious and stressed all the time."
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
with torch.no_grad():
logits = model(**inputs).logits
prediction = torch.argmax(logits, dim=1).item()
labels = ["Stress", "Depression", "Bipolar", "Personality Disorder", "Anxiety"]
print(f"Predicted Category: {labels[prediction]}")🔗 Explore the app UI here: Hugging Face Spaces
🚀 mindBERT – Advancing AI for Mental Health Research!